A practical example of how AI and Data Science can be used when dealing with predictive analytics. Don't reinvent the wheel, try our Python templates!
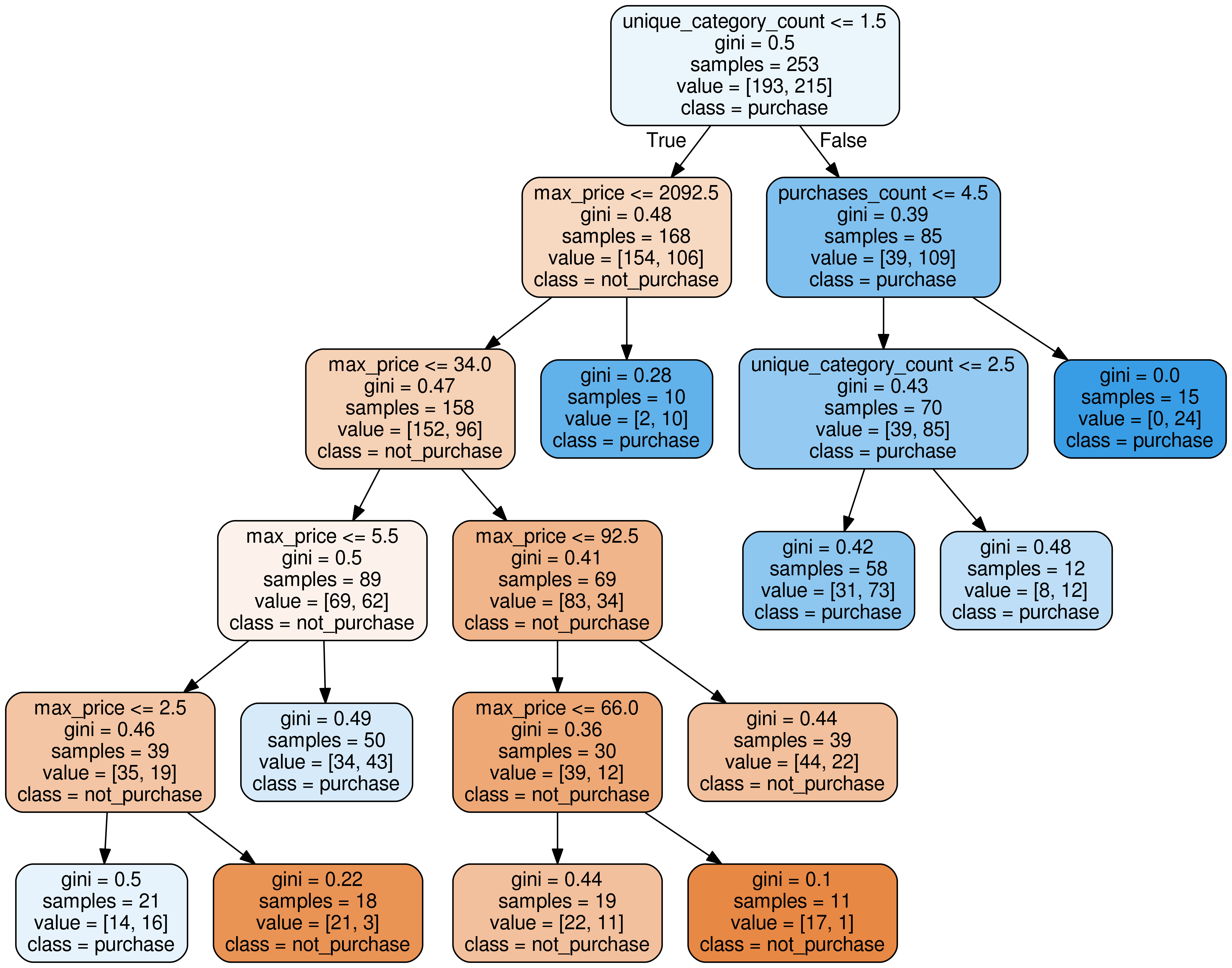
A practical example of how AI and Data Science can be used when dealing with predictive analytics. Don't reinvent the wheel, try our Python templates!

Our "Unlocking AI potential in e-commerce and online business" series aims to provide basic guidance on applying AI. How AI could be used to predict future?
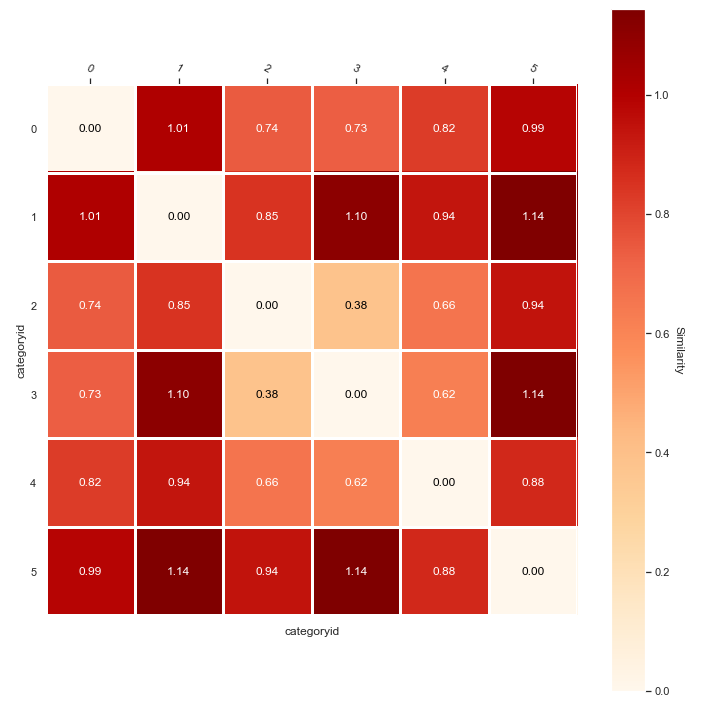
A practical example of how AI and Data Science can be used when dealing with content personalization. Don't reinvent the wheel, try our Python templates!

Our "Unlocking AI potential in e-commerce and online business" series aims to provide basic guidance on applying AI. How AI could be used to make content personalization better?

Our "Unlocking AI potential in e-commerce and online business" series aims to provide basic guidance on applying AI. How to deal with ethical issues in AI?