
Welcome! Our “Unlocking AI potential in e-commerce and online business” series aims to provide basic guidance on applying AI (Artificial Intelligence) in businesses which use the internet as a primary source for delivering value to their customers. In this article, we focus on ethical aspects of training and using AI models.
- AI is biased
- AI is sexist
- AI is racist
- AI is unfair
- AI is not reliable
- Can we trust AI? Who is responsible for the decisions it makes?
We see headlines like that more and more frequently. Especially in human resources, in healthcare and in almost every field where people data is being used for machine learning. Our last article revealed what is happening behind the scenes of selected artificial intelligence models. Let’s put these insights into context. Enjoy your reading!
Are you new to AI and Machine Learning? If so, we recommend the first article in our “Unlocking AI potential in e-commerce and online business” dealing with basic concepts.
Black mirror
The Confederation of British Industry published a report recently, recommending companies to “monitor” decisions made by artificial intelligence and conduct an audit of how personal data is being used. Many officials and decision makers are aware of the disruption AI could bring to many industries and everyday life.

In the EU, for example, the General Data Protection Regulation (GDPR) could be considered as an official response to new, data-powered technologies. Similarly, the California Consumer Privacy Act (CCPA) sets the bar for U.S. companies. It is probably just a matter of time before lawmakers in other states and countries follow.
In this article, we will not comment on the political dimension of the whole thing. Instead, we will focus on practical information which could be used on a daily basis.
During the last Fall, there was much talk about Amazon scraping its AI recruiting tool. The reason for that was a bias towards the word “women” in CVs. Similarly, the Google Photos tool faced embarrassment caused by machine learning because it labeled a photo of a black couple as “gorillas”. How is something like that even possible? Data.
As you sow…
In a way, we can think of machine learning as a tool for making a mathematical representation of the training data. In her research, Dr. J.J. Bryson, an AI expert from the University of Bath, states, that if we apply machine learning to historical text data, we will implicitly include historical biases as well. Likewise, if we train our NLP (Natural Language Processing) model on texts from the current human discussions, we need to deal with current stereotypes.
AI is not a black box, AI is a black mirror
But here comes the question – who will decide what is still acceptable and what has crossed the line? Is it possible to develop “fair” artificial intelligence? If we want to try, we need to think about related issues:
- What kinds of stereotypes could be present in the population that produces our data?
- Is it possible to identify bias in our training data for machine learning?
- Which features are connected to discrimination and could potentially cause the model to behave unfairly?
The “risky” variables are obviously race, gender and similar “human features”. The problem is that in some cases it is precisely this information that determines the right product or service for the customer. For instance, skin color and skin type could be quite important when training a recommender for cosmetic products.
How to deal with data selection and knowledge representation in AI projects? You can find a few tips in the third article in our “Unlocking AI potential in e-commerce and online business” series!
When preparing the training data, it is good to consider not only the business domain (or the product category) but also the moral boundaries of the target customer segment which will be the source of our data or the end user of our model.
Training the “censor”
Another tough thing for AI is to distinguish what is meant for real and what is just humor, irony or sarcasm. If we think about it, the discovery of such language constructions needs a deeper understanding of the context. Let’s face it, sometimes it is not only difficult for an artificial intelligence. Joking aside, the real problem is when it comes to online content moderation. The Verge nicely describes such troubles in companies like Facebook.
We can always prepare the training data by hand and sort particular phrases as “right” or “bad”; nevertheless, without capturing what exactly makes things funny, our AI will probably just memorize particular sentences without the ability to generalize. It makes much more sense to build a rule-based tool which sends every suspicious content to the moderator for approval or to filter it out, just to be sure.

Anyway, we need to decide to what extent we are willing to censor free speech. The fundamental question is:
- Do we want to use AI to improve our products and services or as a tool for enforcing our own beliefs?
In the previously mentioned example of labeling a black couple as “gorillas” we can see how Google approached the problem. Two years after the embarrassment, Google Photos preferred to ignore gorillas completely.
Everything is relative, everything is subjective
We have already suggested that some problems are difficult not only for AI but for humans as well. Are we, humans, intelligent enough to create something which might one day replace our own decisions? Let’s think about how our thought process works and how to use this knowledge to design AI.
Illusion
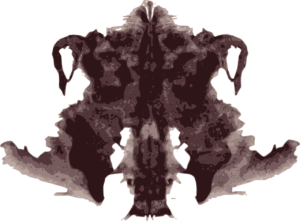
No matter whether we are reading a text or looking at a picture, we always base our decisions on our knowledge and experience but, most importantly, on our own subjective feelings. This principle inspired the Swiss psychologist Hermann Rorschach to create his famous inkblot test. A subject (human) is presented with a series of inkblots and is asked to describe what is on the picture. The individuals’ thoughts and feelings are involuntarily projected into the vague shape of the inkblot.
Using a bit of imagination, we can say that artificial intelligence faces the Rorschach test each time it’s presented with testing data. The input is usually a feature vector – a particular combination of numbers or encoded information. Unfortunately, it often lacks context and the option to ask for more details. The output of the model is basically a “melt-down product” of training samples, which are most similar to the input by the chosen metric.
Data with multiple meanings is tough for AI as well. This applies to images and language but also to the other types of data such as signal or online events.
Connecting the pieces
As mentioned earlier, our brain uses knowledge and context information in addition to historical data. Let’s illustrate this in these two images. Which bear is alive?

The correct answer is picture 1. What kind of knowledge and contextual information did we use to solve this puzzle?
- The bear is moving: We know about the existence of such a thing as movement. We are aware that some kind of force is needed for movement to happen. We also know that this force needs some kind of source. We have a basic knowledge of a bear’s anatomy as well. The position of the bear’s body suggests that the source of the movement force is probably the bear itself. Only live bears are able to move on their own.
- Water splashing and wet fur: We know about the existence of such a thing as water. We are able to detect it because it looks transparent. We know it could be presented in the form of a river or lake. We have a basic knowledge of physics and we know that some kind of force must be applied to make the water splash. We also know that a bear’s fur looks different when it comes into contact with water. The bear’s fur has wet spots and the position of the bear’s body suggests that it’s the source of the force which causes the water to splash. Only live bears are capable of such a thing.
- The bear is fighting with another bear: We have some basic knowledge about bears and their natural habits such as fighting for food or territory. We know what a fight is and what it looks like. We also know that it could occur between two live individuals. Only live bears are capable of fighting.
How do we know that the bear in picture 2 is not alive? Apart from the water splashing and the fighting, we could apply several thoughts in the same way as in picture 1. The bear looks quite natural and it also seems to be moving. The key evidence is the small label stating “Grizzly Bear” which is placed in front of the bear. We know about the existence of such things as a museum and taxidermy. We also know that in the museum, exhibits are usually marked with labels. Live bears don’t use labels.
What did we just do?
- A decomposition of the problem into parts
- Each part of the problem was solved separately, using relevant domain knowledge and experience
- A synthesis of partial solutions into the final result
In this case, our decision-making process could be described as a fallback model which returns the most probable option and improves its accuracy with every further piece of evidence.
We can use a similar approach to machine learning when solving a complex problem. The final solution can be a combination of several models specializing in particular domains. As well as image recognition, fake news detection could be used as an example for this case – suspicious content can be decomposed into single statements, these statements can be validated, and these partial results can be synthesized into the final decision. Our success depends on how well we are able to capture the context information using available data.
How to successfully execute AI-related projects? You can find a few tips in this article in our “Unlocking AI potential in e-commerce and online business” series!
I know how to deal with ethical issues in AI, what next?
If you want to benefit from AI, you need a few things; proper understanding of an AI project life cycle, the right data and the right people. We will cover all these aspects in our series “Unlocking AI potential in e-commerce and online business”. Stay tuned!
About the author
My name is Ondřej Kopička and I help companies automate data analysis.
Does the volume of your data exceed the capacity of your analysts? Then we should talk.
Connect with me on LinkedIn: https://www.linkedin.com/in/ondrej-kopicka/



